|
Home | Search | Browse | About IPO | Staff | Links |
|
Home | Search | Browse | About IPO | Staff | Links |
|
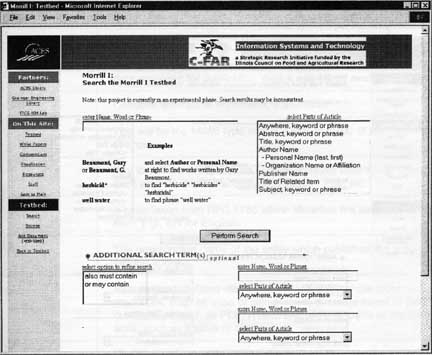
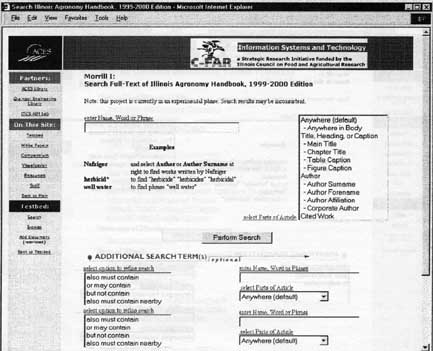
Building an Outreach Digital Library Collection Timothy W. Cole, Robert S. Allen, and John G. Schmitz University extension services are finding the World Wide Web an increasingly useful tool in their efforts to fulfill outreach mission objectives. Documents aimed at off-campus users and previously published only in paper format are now being published in HTML or PDF and made available to end-users via the Web. The challenge for the academic library is to help organize and facilitate access to these online resources as it has for equivalent paper format resources in the past. This article describes the results and lessons learned from an effort at the University of Illinois at Urbana-Champaign (UIUC) to build a prototype outreach information system to do just this for a collection of educational resources in the field of agriculture. Funded in part by the Illinois Council on Food and Agricultural Research, the project is a collaborative effort of the UIUC Library and the Agricultural Instructional Media Lab of the UIUC College of Agricultural, Consumer and Environmental Sciences (ACES). The prototype system created as part of this project demonstrates technologies that can be used to organize and index a diverse collection of online text resources. The collection includes online versions of pamphlets, circulars, newsletters, handbooks and technical reports published by ACES and the UIUC Cooperative Extension Services. Links to related state and federal governmental resources augment the collection of UIUC resources. Where copyright allows selected older resources held by the ACES Library are being scanned, OCR'd, and incorporated into the test-bed. Metadata is created for each item indexed. The searchable index contains a combination of metadata and complete or partial full text of the source documents. Selected resources are being converted to XML to assess the potential of that format to enhance search functionality. Introduction Distance education and online extension services are becoming increasingly important and vital components of the work performed and services provided by today's land-grant universities. Researchers now routinely expect to conduct a large portion of their research online; citizens served want quicker, more convenient access to the resources of their publicly funded institutions; and legislatures are demanding maximum value for the dollar. Knowledge on demand, anywhere, anytime, has become a goal for institutions of higher education. Simultaneously, end-users of information are becoming increasingly aware of online search and retrieval systems. The advent and aggressive marketing of Web search engines that purport to return the best information available in response to complex natural language queries has introduced users to key architectural concepts of digital libraries. They have come to appreciate seamless access to information maintained on systems physically located in multiple remote locations. They are beginning to learn about the features that make for more interactive and effective search interfaces. They expect extensive, bi-directional linkage between online documents on related topics. The problem is that while digital library concepts are becoming increasingly known to the average user, real, full-fledged digital analogs to brick and mortar libraries are still to be built. It is clear that for now expectations of Web searching exceed capability by a large margin. Recent estimates indicate that less than a quarter of the available Web resources is searchable by any particular Web search engine. Results returned by Web searches are often massive in number and of low quality, requiring careful checking of myriad links to find desired resources. A related limitation is that searches do not pinpoint where in a resource the desired information * Timothy W. Cole (t-cole3@uiuc.edu), associate professor and interim mathematics librarian; Robert S. Allsen (allen2@uiuc.edu), associate professor and agricultural, consumer, & environmental sciences librarian; and John G. Schmitz (jschmitz@uiuc.edu), manager, Agricultural Instructional Media aboratory; University of Illinois at Urbana-Champaign. This paper was presented at the Illinois Association of College & Research Libraries (IACRL) Forum Conference, April 13-14, 2000, in Matteson, Illinois. Principal support for research was provided by the Illinois Council on Food and Agricultural Research and the Intel Corporation Illinois Libraries, Fall 2000 239 resides. Key digital library infrastructure technologies — e.g., rich and fully extensible markup schemata, standards and best practices for the creation of metadata, flexible, powerful and robust full-text search and retrieval systems — still need to be better defined, developed, tested, and implemented. Project Overview In fall 1998, the Illinois Council for Food and Agricultural Research (C-FAR) funded a project at the UIUC to investigate technologies required to create and make accessible a digital library collection in the domain of agriculture and agricultural sciences. The project has been a collaborative effort of the UIUC Library and the Agricultural Instructional Media (AIM) Laboratory, a unit of ACES. Augmented in fall 1999 with an equipment grant from the Intel Corporation, the project has created a small-scale prototype outreach information system. The expertise and technologies developed as part of this work will help inform and define systems and services that will be implemented in the new and expanded ACES Library, scheduled to be open before fall semester 2001. The initial task of the project was to identify items representative of library materials used in conjunction with outreach programs and appropriate for inclusion in a digital library serving such programs. Having identified the different classes of materials that were to be included in our prototype, the next step was to investigate and test technologies and processes that would support the acquisition and organization of these materials so as to facilitate access and use. Particular attention was paid to metadata generation and the design and implementation of a full-text search and retrieval system. Along the way, issues were discussed with document publishers, both to help us better understand trends in publishing of these resources and to help them better understand the ways in which the materials they produce may be used in the future. The end-result to date, a small-scale prototype of a digital library / outreach information system, serves as a testbed for experimentation with and demonstration of the technologies involved. Testbed Collections The process of building a collection for an online digital library differs in several respects from the process used to build a print-based collection. While much of the intellectual content is similar, items in a virtual collection are typically widely dispersed, often on servers not under the control of the library (raising significant archiving, availability and index building concerns). Content is more dynamic and the discrete units and formats of content may vary significantly (also having an impact on archiving and indexing). Intellectual property and rights issues must be handled differently. An academic outreach digital library collection will include not only items identifiable as books, journals, pamphlets and reports, but individual Web pages, entire Web sites, courseware and other software application objects, database objects, even portals and other access points to dynamic and possibly overlapping collections. Inclusion of pointers to overlapping online collections of resources raises "appropriate copy" issues (Caplan & Flecker, 1999). Some items will have analogues in paper collections, some will not. Even traditional items such as books may be accessible and/or viewable in different ways (e.g., handbooks may be retrievable piecemeal and may include multimedia extensions or links to addenda and commentary added after initial publication). For some time to come formats and associated display quality and flexibility will vary. While XML eventually may supplant the more limited HTML specification as the Web format of choice for text, systems will need to support both formats for the foreseeable future. PDF and other high-quality proprietary formats will continue to be used. Some older materials will be available only as scanned images. To create our prototype collection we focused on examples that were relatively static, primarily textual, and available free of charge (to limit intellectual property issues). We included online versions of ACES-published handbooks and guides; State of Illinois statistical reports. Extension Service circulars, fact sheets and newsletters; Experiment Station serials, digests and program reports; etc. Documents in HTML, XML and PDF formats are included in the prototype. Several of the PDF items we included were created by scanning older reports and then converting using Adobe Acrobat. (Acrobat's built-in OCR tool was used to generate unstructured full-text for such scanned documents.) An illustrative compendium, organized by publishing institution or unit, was created to provide simple browse access to the prototype collection of online materials. This browse interface provides access not only to specific items published by UIUC organizations, but also links to web sites of other organizations 240 Illinois Libraries, Fall 2000 that provide related services and/or similar, relevant collections. Figure 1 shows the range of publishers represented in our prototype system browse interface. Such a virtual, distributed collection model raises numerous issues. What defines adequate archiving of materials in such a distributed collection and how is such a level of archiving assured? In the event of overlaps among the virtual collections of the linked sites, how is the user assured of getting access to the most appropriate copy? (e.g., if an item is available both under an institutionally licensed arrangement and as a pay-per-view item directly from the publisher, how does the system make sure the user is directed to the institutionally licensed copy?) How is an index to such a distributed collection built and maintained? While the appropriate copy and long-term archiving issues raised by this model have not yet been fully addressed in our project, we have designed and implemented a search and retrieval interface to a subset of the content available from the browse interface. This allowed us to explore digital library search and retrieval issues in greater depth. Approaches used to index the items in the collection subset ranged from full-capture and reformatting of documents (e.g., the ACES-published Illinois Agronomy Handbook was captured and transformed into XML) to representing items in the index using metadata only. Realistic resource budgeting and the distributed and dynamic nature of digital collections argue for some compromise approach, relying on an index containing both metadata for each item and full-or partial-text content of items when available (and when permissible to capture). Exposed structure of the full text can be used to enhance search and retrieval as much as allowed by the markup schemata used. Metadata Issues The metadata record for a digital object typically contains both descriptive and functional information. The item is described in a manner to facilitate discovery and assist in collection maintenance. Metadata may include technical information about how an item may be used, as well as information about conditions of use (e.g., license fees, who is allowed to use which parts of the object for which purposes, etc.). Metadata also will frequently contain version information, about how the item relates to other online (and sometimes paper) objects, and/or information about the multiple ways in which an item (or portions of an item) may be accessed and viewed. Taken to an extreme, metadata records describing items in a digital library collection could routinely exceed in size the text being described, especially given that online items are frequently smaller and more discrete than print counterparts. Such extreme investment is rarely warranted and even less often practical. To generate enough metadata at a low enough cost, a combination of techniques must be employed. In addition to manually generating parts of the metadata records, digital library systems also rely on existing metadata when available (e.g., MARC records describing print versions of the same content) and on auto-generation algorithms that extract metadata from the document itself. This latter approach is especially useful when dealing with collections containing well-encoded XML documents. The definition of what is "enough" metadata remains fluid. For our project we began with the Dublin Core (DC) metadata element set (Dublin Core Metadata Initiative, 1998). Though there remains some variation in how this schema is implemented by different projects and work to further refine the schema continues, this element set is becoming something of a lowest common denominator for many bibliographic database projects. The selection of DC elements we use and the purpose for which we use each element is shown in Table 1. While a good starting point and a good schema to insure interoperability, our experience indicates a need for at least some additional granularity. In conjunction with another text-based digital library project underway at the UIUC Library (Schatz, 1999; Arms, 1999), we developed a supplemental set of metadata elements to be used in combination with DC elements. Some of these elements were designed to require specific attributes. The list of supplemental elements and each element's associated attributes is given in Table 2. This list is extensive and the elements included are intended to be used selectively - as most appropriate for a given application. This two-part metadata schema has been implemented in our prototype system through the use of Web forms. Authorized users may add items to the searchable collection by entering available metadata on the form and submitting it to the Web server. The metadata is captured from the submitted form and, when available, the document itself is downloaded to our server for indexing and to allow additional metadata extraction. For HTML and XML documents, additional metadata auto-generated from the source document Illinois Libraries, Fall 2000 241 may include information such as external links, document title and author information, author affiliation information, etc. - depending on the richness of the original markup. The metadata is then stored in an SQL-compliant database. Metadata is searched along with full-text content. Item-specific metadata records can be extracted from the database and displayed individually. Such records are encoded consistent with the Resource Description Framework (RDF) recommendation of the W3 Consortium (W3C, 1999), which in turn is an XML schema. DC elements are repeated as appropriate, contained within RDF container elements (e.g., BAG, SEQ, ALT). Indexing and Search of Full-Text The creation of metadata as described helps to normalize and facilitate search of our digital library sample collection. We also index full-text content of the items to maximum extent possible. Because this searchable index is never used to regenerate the original source document (rather the original source URL is always provided), any non-essential tagging is discarded. For XML and HTML items, we preserve document structure information useful for item discovery. Text data contained in HTML title tags, anchor tags and appropriate meta tags are indexed both individually and as part of the document full-text. XML encoding that makes use of selected SGML tag names defined in the ISO 12083 Book and Article DTDs (Kennedy, 1999) is also preserved and indexed. Table 3 is a list of the ISO 12083 elements that are indexed and/or extracted automatically for inclusion in the metadata. Making use of explicit document content models when available provides a richer, albeit potentially less even, search index and allows for a more functional search interface. Figure 2 shows the prototype system's current metadata-only search interface. In this interface, full-text content, if present at all, is assumed to be undifferentiated for searching purposes. It is only searched simultaneously with metadata. Fielded searching can only be done against available metadata fields, which should be present for all items. Figure 3 shows a similar search interface that assumes the structure of the document itself can be searched. Obviously, searches of specific fields in the document will not find documents for which such structural information is unavailable. (Note - the search interface shown in Figure 3 suppresses the searching of some metadata fields searchable in the interface shown in Figure 2.) The tradeoff between the two search approaches becomes a tradeoff between precision and recall. More precise searches can be done by specifying document fields to search, but some recall is sacrificed because not all the documents expose the same level of structural detail. The decision of which approach is better for a particular collection should be based on the characteristics of the collection. How rich is the metadata? What percentage of the documents lack basic structural markup? Discussions with document publishers indicate that there remains a wide variation in the standardization and rigor of markup approaches being used today. In general, current techniques employed in this domain are not sophisticated. Some publishers of outreach materials are making an effort to markup HTML consistently enough to allow certain content structures to be inferred, at least within their own organization (e.g., authors are always shown in H3, italics). However, our experience indicates that it is expensive to make use of such implicit "understood" practices in even a modest-sized digital library collection. There are simply too many different publishers involved, and consistency over time is too unpredictable. More explicit mechanisms, such as with XML or through the use of the HTML class attributes, should be employed; however, as of yet, such techniques are not being widely or consistently used in this domain. Further work to develop XML schemata and/or markup best practice standards for outreach and extension publications remains to be done. Assuming such schemata and standards are developed, then the expectation as time passes will be that it will become easier for users to find newer, better encoded items, and harder for them to find older documents for which full-content and/or well-differentiated content is not available. This is appropriate in an information system where more current publications can be considered more important, but arguably may not be appropriate in other settings. In other situations, additional retrospective work may be required to ensure all items in the collection are equally represented in the index. Alternatively, the decision may be to index to the lowest common denominator - i.e., to build search indexes and interfaces based on the minimum markup standards represented in the collection. Conclusion The ease with which information can be mounted on the Web belies the challenge and expense of organizing that information and making it easy to find. While the 242 Illinois Libraries, Fall 2000 project described here demonstrates the potential of the technologies available, it also illustrates how time-consuming and labor-intensive the process of constructing a digital library is. To deal with the diversity and amount of relevant online information being generated every day, a balance must be struck between the labor-intensive work of manually creating metadata and the equally labor-intensive work of using high-fidelity mark-up schemata to adequately expose document structure. Achieving this balance will require that university libraries work even more closely than they have in the past with publishers of information, both within and outside of the institution. It also will require that the agricultural extension and outreach community work diligently to develop standards and best practices for both markup and metadata creation, and that we continue to study the information seeking behaviors of our end-users to better inform the development of those standards and best practices. Small prototype testbed projects such as the one described will help us to better investigate both the technologies and the use of those technologies by end-users in practical contexts. References Arms, William Y.,etal. (1999). "The D-Lib Test Suite: Testbeds for Digital Libraries Research," D-Lib Magazine, 5(2) [online]. Available: " http://www.dlib.org/dlib/february99/arms/02overview.html [13 March 2000]. Caplan, Priscilla and Dale Flecker (1999). Choosing the Appropriate Copy: Report of a Discussion of Options for Selecting Among Multiple Copies of an Electronic Journal Article [online]. Available: http://www.niso.org/DLFarch.html [10 March 2000]. Dublin Core Metadata Initiative (1998). The Dublin Core: A Simple Content Description Model for Electronic Resources [online]. Available: http://puri.oclc.org/dc/_ [29 February 2000]. Kennedy, Dianne (1999). ISO 12083 Information [online]. Available: http://www.xmlxperts.com/12083.htm_[13 March 2000]. Schatz, B., et al. (1999). "Federated Search of Scientific Literature: A Retrospective on the Illinois Digital Library Project." IEEE Computer, 32(2), 51-59. W3C: World Wide Web Consortium (1999). Resource Description Framework (RDF) Model and Syntax Specification: W3C Recommendation 22 February 1999 [online]. Available: http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/ [29 February 2000]. Illinois Libraries, Fall 2000 243
Figure 1 - From the Prototype Website 244 Illinois Libraries, Fall 2000
Figure 2 - Metadata Search Interface Illinois Libraries, Fall 2000 245
Figure 3 - Full-Text Search Interface; Assumes Extensive Full-Text Structure 246 Illinois Libraries, Fall 2000
Table 1 - Dublin Core Elements Used Illinois Libraries, Fall 2000 247
Table 2 - UlUC-specific Metadata Elements & Attributes (cont.) 248 Illinois Libraries, Fall 2000
Table 2 - UlUC-specific Metadata Elements & Attributes (cont.) Illinois Libraries, Fall 2000 249
Table 2 - UlUC-specific Metadata Elements & Attributes
Table 3 - ISO 12083 Book & Article Tags Indexed 250 Illinois Libraries, Fall 2000 |
|
|